In previous posts I’ve talked about how the DSLWP-B 70cm signal can sometimes be received in the Dwingeloo 25m radiotelescope via a reflection off the Moon’s surface. I’ve studied the geometry of this reflection, the cross-correlation against the direct signal, and even decoded some reflected JT4G.
However, so far the reflection has been detected by hand by looking at the recording waterfalls. We don’t have any statistics about how often it happens or which conditions favour it. I want to make some scripts to process all the Dwingeloo recordings in batch and try to extract some useful conclusions from the data.
Here I show my first script, which computes the power of the direct and reflected signals (if any). The analysis of the results will be done in a future post.
The scripts and data can be found here. The main script is called process_recording.py. This takes a 40ksps IQ recording from Dwingeloo and processes it as follows.
First, it looks in a directory of tracking files (as published in dslwp_dev) to find the nearest to the recording timestamp. This tracking file is taken as the orbital state to propagate the orbit in GMAT.
The Python script runs a GMAT simulation that creates a report file that allows us to compute the direct and Moonbounce Dopplers. The Moonbounce Doppler is computed by the method described here.
The IQ recording is first Doppler corrected using the direct Doppler curve. Power spectra are taken and summed over all the recording to produce a spectrum of energy spectral density. This spectrum is then used to find the DSLWP-B GMSK signal, which can be up to 1kHz away from its nominal frequency, due to drift in the transmitter and receiver clocks. The baudrate (either 250baud or 500baud) is also detected.
The algorithm used to detect the GMSK signal is a simple channel detection algorithm that nevertheless has worked OK. The algorithm runs only over the central spectrum bins, where the GMSK signal is expected to be found. Each bin is deemed as noise or signal by comparing whether its power is lower or higher than a threshold. The threshold is defined as the median power plus one half of the standard deviation of the power (this was found to work well by some trial and error of different thresholds).
Adjacent signal bins are aggregated in a channel, producing a list of channels and its bandwidths (defined by the number of bins comprising the channel). Then the power of each channel is estimated by taking the power of its central bin. Now we iterate the list of channels, in decreasing order of channel power, checking whether each channel’s bandwidth is compatible with a 250baud or a 500baud GMSK signal (using some some very gross margins for the allowable bandwidths). When we find a match, we tag that channel as our GMSK signal and stop.
If no GMSK signal has been detected, the execution stops, dumping the spectrum to a “rejected spectrum” file for later examination. If a GMSK signal is found, its frequency offset is noted and it is included in further Doppler correction to centre the signal at 0Hz.
After detecting the GMSK signal, we compute the spectrum of the direct and Moonbounce signals by correcting with each of the Doppler curves (including the frequency offset) and computing and summing spectra as before. The summed spectra are saved in a file.
After this, the power versus time of the direct and Moonbounce signals is computed as follows. The IQ recording is Doppler corrected, lowpass filtred with a bandwidth depending on the GMSK baudrate, and average RMS power readings are taken. The power measurements are also saved to a file.
In my script I am using xarray and Dask. Xarray gives me a good way of handling and tagging the data, and saving the results to NetCDF4 files. Dask is a very nice library that allows me to define lazy computations that will execute by blocks. With this, I avoid loading the 2GB IQ recordings in RAM, while also getting parallelism for free. All the signal processing on IQ recordings is done using Dask.
The shell script process_all_recordings.sh can be used to process all the IQ recordings, by calling process_recording.py for each IQ file. It should be run indicating the path to a directory holding all the recordings as first argument and the path to a directory holding all the tracking files as second argument. A nice thing about process_recording.py is that it doesn’t do the calculations again if it detects that the corresponding output files exists, so the process_all_recordings.sh script can be run again when new IQ recordings are added, without needing to reprocess everything.
The processing of all the Dwingeloo recordings takes almost 4 hours to run in my laptop. I have included the output folder to save other people from having to process the recordings.
The plot_spectrum.py script scans this output folder and makes a plot of each spectrum. This can be used to check that the GMSK signal has been detected correctly in all the recordings. This is the case in all the files, except in the 2018-10-25T18:49:54 recordings, which do not contain any DSLWP-B signals.
As an example of the output of the batch processing, I have included the Plot data.ipynb Jupyter notebook, which shows the output for the 2018-10-07T11:30:45_436.4MHz file, which I have analysed before in my Moonbounce post. The figures below show the results.
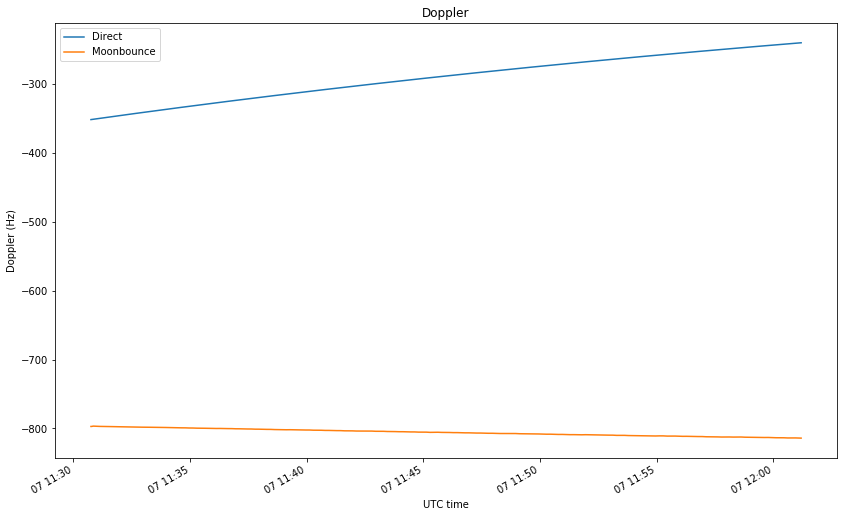
The Doppler plot shows that the Doppler curves are well separated, allowing us to distinguish the direct and Moonbounce signals. This only happens in certain geometric configurations.
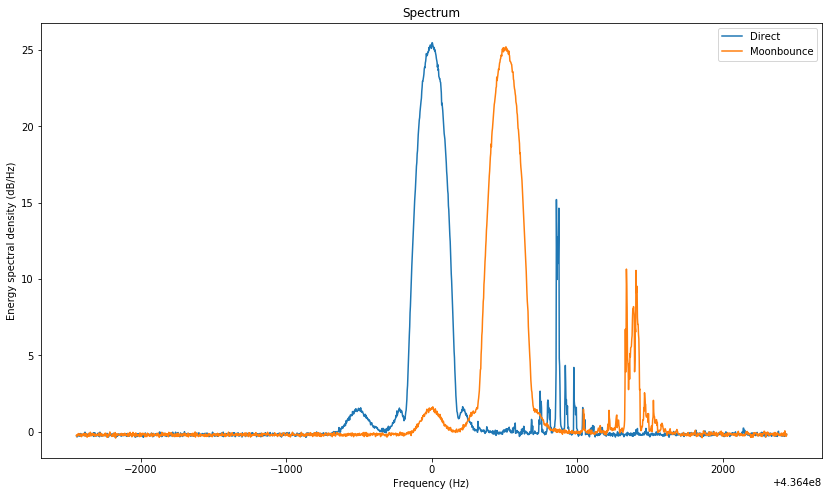
The direct spectrum, in blue, shows a very strong direct signal at 0Hz and a small bump around -500Hz. This is the Moonbounce signal. When correcting for the Moonbounce Doppler, the orange spectrum shows the Moonbounce signal at 0Hz. The remaining signals are interference, which can be problematic for the GMSK detector or for the power calculation.
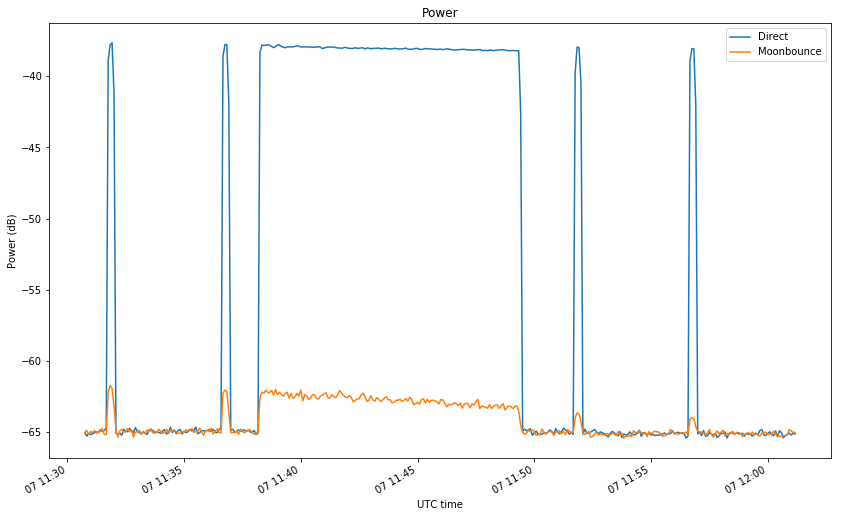
The power versus time plot shows that the Moonbounce signal is about 25dB weaker than the direct signal and that it gets weaker towards the end of the recording.
2 comments